Diagnosing Index Bloat: Optimizing Medical Site Visibility
This article provides a technical SEO workflow for diagnosing index bloat on medical websites. The process identifies and resolves instances where search engines index excessive low-value or duplicate pages, which wastes crawl budget and dilutes the authority of critical YMYL content. Readers will learn to identify common causes such as thin content, URL parameters, and improper canonicalization. The workflow emphasizes strategic solutions, including effective noindex tags, robust site architecture, and log file analysis, to ensure high-value medical service pages and practitioner profiles achieve optimal organic visibility and search engine trust.
Abdurrahman Şimşek, a London-based Semantic SEO Strategist with 10 years of experience, specializes in building high-authority Semantic Content Networks for medical clinics. His expertise in technical SEO, information retrieval, and medical content configuration ensures precise indexing and enhanced organic performance for healthcare providers.
To explore your options, contact us to schedule your consultation.
For medical websites, maintaining optimal search engine visibility is paramount. A critical step in achieving this involves effectively diagnosing index bloat. This phenomenon occurs when search engines index an excessive number of low-value or duplicate pages, consuming valuable crawl budget and diluting the authority of essential medical content. This article outlines a technical SEO workflow to identify and resolve index bloat, ensuring your high-value service pages, practitioner profiles, and educational resources receive the attention they deserve from search engines. Understanding and addressing index bloat is fundamental for enhancing organic performance in the competitive healthcare sector.
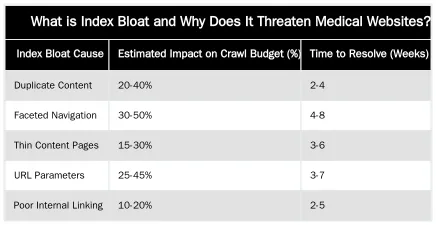
What is Index Bloat and Why Does It Threaten Medical Websites?
Index bloat describes a situation where a search engine’s index contains a disproportionately high number of low-quality, duplicate, or irrelevant pages from a website. This over-indexing wastes a site’s allocated crawl budget, meaning search engine bots spend less time discovering and re-crawling valuable content. For medical websites, this is a significant threat because it can dilute the authority of critical YMYL (Your Money Your Life) content, such as treatment descriptions, doctor bios, and patient information, impacting their ability to rank for high-value queries.
Medical websites are particularly susceptible to index bloat due to their complex nature. They often feature extensive service pages, numerous practitioner profiles, dynamic booking systems, and faceted navigation for filtering treatments or doctors. Each of these elements can inadvertently generate countless URL variations or near-duplicate content. When search engines index these low-value pages, it can obscure the authoritative, expert-reviewed content that truly serves patient needs, ultimately hindering organic visibility and trust signals.
Common Causes of Index Bloat on Medical Websites
Understanding the root causes of index bloat is the first step toward remediation. Medical websites, with their specific content and functional requirements, often encounter unique challenges that lead to an inflated index.
Duplicate Content & Thin Pages: A Medical Site’s Vulnerability
Duplicate content is a primary contributor to index bloat. On medical websites, this often manifests as identical service descriptions used across multiple clinic locations without proper canonicalization. Boilerplate content, such as disclaimers or privacy policies repeated on numerous pages, can also be flagged as low-value. Furthermore, auto-generated pages like old event listings, appointment confirmation pages, or internal search results that offer little unique value to users can be inadvertently indexed, creating a large volume of thin content that dilutes overall site quality.
Faceted Navigation & URL Parameters: Hidden Bloat Generators
Faceted navigation, commonly found on doctor directories, treatment category pages, or product listings for medical devices, is a significant source of index bloat. Each filter applied (e.g., “dermatologist in London,” “acne treatment,” “available on Tuesday”) can generate a unique URL. If not properly controlled, search engines may crawl and index thousands of these filtered URLs, most of which offer minimal unique content. Similarly, poorly configured URL parameters from booking systems, tracking codes, or session IDs can create endless variations of the same page, leading to extensive and unnecessary indexing.
A Technical SEO Workflow for Diagnosing Index Bloat
A systematic approach is essential for identifying and addressing index bloat. This workflow leverages key SEO tools to pinpoint areas of concern and guide remediation efforts.
Leveraging Google Search Console for Initial Diagnostics
Google Search Console (GSC) is an indispensable tool for initial index bloat diagnostics. Begin by examining the ‘Pages’ report under ‘Indexing’. This report provides an overview of indexed pages versus those excluded, along with reasons for exclusion. Look for a high number of ‘Crawled – currently not indexed’ or ‘Discovered – currently not indexed’ pages, which can indicate crawl budget issues. The ‘Coverage’ report helps identify indexing anomalies, such as pages with soft 404s or those marked as duplicates. Additionally, the ‘Crawl Stats’ report offers insights into Googlebot’s activity, revealing how much of your crawl budget is being spent on low-value URLs. A sudden spike in crawled but not indexed pages, or a high percentage of crawl activity on URLs you deem unimportant, signals potential bloat. For a deeper dive into resolving these issues, refer to our guide on fixing indexing issues in 2026.
Uncovering Issues with Log File Analysis
While GSC provides a high-level view, server log file analysis offers granular detail into Googlebot’s actual crawling behavior. By analyzing log files, you can see precisely which URLs Googlebot requests, how frequently, and its response codes. This data helps identify wasted crawl budget by revealing if Googlebot is spending significant resources on pages that should not be indexed (e.g., internal search results, old parameters, staging environments). Key metrics to look for include a high volume of 200 OK responses for low-value URLs, or repeated crawling of pages that are already canonicalized or noindexed. This analysis is crucial for understanding the true cost of retrieval (CoR) for your website. For a comprehensive approach to managing crawler activity, explore our crawl budget optimization workflow.
Strategic Solutions: Canonicalization, Noindex, and Site Architecture
Effective management of index bloat requires a nuanced application of technical SEO directives. As a semantic SEO strategist specializing in medical clinics, Abdurrahman Şimşek emphasizes a holistic approach that integrates these solutions with a robust site architecture.
Mastering Canonical Tags for YMYL Content
Canonical tags (`rel=”canonical”`) are vital for consolidating authority, especially for Your Money Your Life (YMYL) content on medical websites. They tell search engines which version of a page is the preferred one to index when duplicate or near-duplicate content exists. For instance, if a clinic offers the same “Dermal Fillers” service across multiple London locations, each with a slightly varied page, a canonical tag should point to the primary, most authoritative service page. Common pitfalls include canonicalizing to a non-existent page or using relative URLs. Best practice dictates self-referencing canonicals for unique pages and absolute URLs pointing to the master version for duplicates. This ensures that link equity and relevance signals are concentrated on the most important content, preventing dilution.
When to Use Noindex vs. Robots.txt for Sensitive Pages
Understanding the distinction between `noindex` tags and `robots.txt` directives is crucial for controlling indexing. A `noindex` meta tag (or X-Robots-Tag HTTP header) instructs search engines to exclude a page from their index, even if it’s crawled. This is ideal for pages you want accessible to users but not visible in search results, such as internal search results pages, thank you pages, patient portal logins, or staging environments. Conversely, `robots.txt` is a directive file that tells crawlers which parts of your site they are allowed or not allowed to access. It prevents crawling, but does not guarantee de-indexing if a page is linked externally. For sensitive medical data or private sections, `robots.txt` can prevent crawling, but `noindex` is necessary to ensure a page is removed from the index if it was previously crawled. For pages that should never be crawled or indexed, a combination of both is often the most secure approach.
Optimizing Site Architecture for Crawl Efficiency
A well-planned site architecture is a proactive defense against index bloat. By structuring content logically and hierarchically, you guide search engine crawlers to your most important pages while minimizing paths to low-value or irrelevant content. This involves creating clear navigation, using internal linking strategically, and ensuring a shallow click depth for core service and practitioner pages. For medical websites, this means organizing treatments by specialty, location, or condition, and ensuring that every critical page is easily discoverable from the homepage. This approach aligns with building robust semantic content networks, where related entities are interconnected, enhancing both user experience and crawl efficiency. A strong architecture naturally prevents the proliferation of unmanaged URLs, ensuring that crawl budget is spent on content that matters. For further insights into technical SEO audits, consider exploring resources on SaaS technical SEO audits, which share many principles applicable to complex medical sites.
Beyond Diagnosis: Reclaiming Crawl Budget & Boosting Medical Site Authority
Resolving index bloat extends beyond technical fixes; it translates directly into tangible benefits for medical practices, enhancing their online presence and competitive edge.
The Impact on E-E-A-T and Search Visibility
A clean, well-indexed website signals higher quality and relevance to Google. By eliminating low-value pages, you concentrate your site’s authority on its most important content. This directly enhances E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) signals for medical practitioners and clinics. When Googlebot efficiently crawls and indexes only your expert-authored articles, detailed service pages, and verified practitioner profiles, it reinforces your site’s credibility. This focused indexing leads to improved rankings for core medical services and conditions, as search engines can more easily identify and prioritize your authoritative content over competitors with bloated indexes. This is particularly crucial in the YMYL space, where trust and accuracy are paramount. For more information on E-E-A-T, consult Google’s guidelines on creating helpful, reliable, people-first content.
Measuring Success: Key Metrics Post-Optimization
After implementing solutions for index bloat, continuous monitoring of key performance indicators (KPIs) is essential to measure success. Look for improvements in Google Search Console’s ‘Crawl Stats’ report, specifically a decrease in crawled URLs that are not indexed, and an increase in crawl activity on your high-value pages. Monitor organic visibility for your target keywords, observing if rankings improve for core services. Track the number of indexed pages in GSC, aiming for a reduction in total indexed pages while maintaining or increasing traffic to your critical content. An increase in organic traffic to previously underperforming high-value pages is a strong indicator of successful optimization. Regularly review your site’s index status to ensure long-term crawl efficiency and sustained authority.

Ready to Optimize Your Medical Website’s Indexing?
Effective management of index bloat is a specialized technical SEO task, particularly for the complex and high-stakes environment of medical websites. If your clinic’s online visibility is hampered by indexing issues, or if you aim to build a robust semantic content network that dominates local organic search across London postcodes, expert guidance is invaluable. Abdurrahman Şimşek, a London-based Semantic SEO Strategist with over a decade of experience, specializes in optimizing medical and aesthetic clinic websites. Partner with an expert who understands the nuances of medical SEO and can implement a tailored strategy to ensure your critical content ranks. Contact Abdurrahman Şimşek today to discuss a comprehensive technical SEO audit and strategy for your practice.
Conclusion
Index bloat poses a significant, yet often overlooked, challenge for medical websites seeking to establish strong organic visibility and E-E-A-T. By systematically identifying its causes through tools like Google Search Console and log file analysis, and implementing strategic solutions such as canonicalization, noindex tags, and optimized site architecture, medical practices can reclaim valuable crawl budget. This focused approach ensures that search engines prioritize and rank their most authoritative content, leading to enhanced search visibility and improved patient acquisition. Proactive management of your site’s index is not just a technical task; it’s a fundamental pillar of a successful medical SEO strategy. For expert assistance in navigating these complexities and building a high-performing medical website, consider partnering with a specialist. Learn more about optimizing your medical website’s SEO.
Frequently Asked Questions
What is the biggest risk of index bloat for a medical website?
The biggest risk is that Google wastes its crawl budget on low-value or duplicate pages. This means your most important, authoritative content—like core procedure pages and physician bios—may be crawled less frequently, delaying updates and impacting rankings. This makes diagnosing index bloat crucial for maintaining visibility.
How can a clinic’s blog contribute to index bloat?
A blog can create index bloat through automatically generated tag, category, and date archive pages. If not handled correctly with ‘noindex’ or canonical tags, these thin-content pages can be indexed in large numbers, diluting the site’s overall quality signals. This is a common area to investigate when identifying indexation issues, and a key step in diagnosing index bloat.
Why is diagnosing index bloat a critical part of a technical SEO audit for medical sites?
It is a critical part of any *technical* SEO audit, often overlooked by generalist agencies. Our process always includes a deep dive into indexation patterns using log file analysis and advanced crawling to ensure the site’s index is clean and efficient. Effective diagnosing index bloat ensures your high-value content is prioritized.
What is the initial step in the workflow for diagnosing index bloat?
The first step is to compare the number of URLs submitted in your sitemap with the number of pages Google reports as indexed in Google Search Console. A significant discrepancy between these two numbers is a primary indicator that further investigation is needed to identify and address bloat.
Can fixing index bloat lead to a noticeable improvement in rankings for medical websites?
Yes. By removing low-quality pages from the index, you consolidate your website’s authority signals onto your most important pages. This often leads to improved rankings for the content that truly matters for patient acquisition, making the effort to address indexation highly valuable.
How can Abdurrahman Şimşek help with diagnosing index bloat and optimizing my medical website?
Abdurrahman Şimşek specializes in holistic SEO strategies for medical clinics, leveraging 10+ years of experience to identify and resolve complex technical issues like index bloat. We provide strategic consulting to reclaim crawl budget and boost your site’s authority. Contact us to discuss a tailored solution for your practice.
Ruxi Data brings together multi-model AI, automated website crawling, live indexation checks, topical authority mapping, E-E-A-T enrichment, schema generation, and full pipeline automation — from crawl to WordPress publish to social posting — all in one platform built for agencies and freelancers who run on results.