
SEO Data Pipeline: Automating SERP Data for Content
An seo data pipeline is an automated system for collecting, processing, and transforming raw SERP data into actionable insights and automated content. This guide details building robust data pipelines, covering ETL processes, SERP scraping, and advanced data transformation techniques. Readers will learn to streamline SEO workflows, enhance content velocity, and drive superior organic performance through structured data and API orchestration. Implementing an effective data pipeline is crucial for modern SEO strategies, enabling scalable content automation and in-depth competitive analysis from real-time analytics.
This article, from abdurrahmansimsek.com, provides expert guidance on leveraging data engineering principles to construct efficient SEO data pipelines. It emphasizes practical strategies for transforming raw SERP data into valuable assets for content automation and strategic decision-making.
To explore your options, contact us to schedule your consultation.
In the rapidly evolving landscape of digital marketing, an effective seo data pipeline is no longer a luxury but a necessity for competitive advantage. This guide will demystify the process of building robust SEO data pipelines, transforming raw SERP data into actionable insights and automated content. Discover how to streamline your SEO workflows, enhance content velocity, and drive superior organic performance by leveraging structured data and advanced automation.
What is an SEO Data Pipeline and Why Does it Matter?
An seo data pipeline is an automated system designed to collect, process, and transform raw Search Engine Results Page (SERP) data into actionable insights and content inputs. This structured approach enables SEO professionals to move beyond manual data collection, facilitating faster decision-making and more efficient resource allocation. It is fundamental for modern SEO strategies, allowing for scalable content automation and in-depth competitive analysis.
In 2026, the sheer volume and complexity of SEO data necessitate automated solutions. A well-constructed seo data pipeline ensures that critical information, from keyword rankings to competitor strategies, is consistently gathered, cleaned, and made ready for analysis. This automation frees up valuable human resources, allowing teams to focus on strategy and execution rather than tedious data handling.
The Core Purpose: Bridging Data and Content Automation
The primary goal of an seo data pipeline is to create a seamless flow between disparate data sources and your SEO initiatives. This includes feeding data into keyword research tools, informing content strategies, and identifying technical SEO opportunities. By automating the extraction and transformation of SERP data, businesses can generate comprehensive content briefs, identify semantic gaps, and even automate parts of the content creation process itself. This bridge between raw data and actionable content inputs is crucial for maintaining a competitive edge in organic search.
How Do SEO Data Pipelines Transform Raw SERP Data?
SEO data pipelines leverage the Extract, Transform, Load (ETL) process to convert raw SERP data into a usable format. This systematic approach begins with extracting data from various sources, followed by rigorous transformation to enrich and structure it, and finally loading it into a destination for analysis or direct application. This process is vital for turning unstructured SERP information into valuable assets for keyword clustering, content brief generation, and competitive intelligence.
Extracting & Cleaning: From SERP Scraping to Data Validation
Data extraction is the initial phase, primarily involving SERP scraping and API orchestration. Tools designed for SERP scraping collect vast amounts of data, including organic rankings, featured snippets, People Also Ask (PAA) boxes, local packs, and competitor ad copy. Simultaneously, APIs from platforms like Google Search Console, Google Analytics, and various SEO tools provide additional layers of performance data.
Following extraction, data cleaning is paramount. This involves deduplication, removing irrelevant entries, correcting inconsistencies, and validating the integrity of the collected information. Ensuring high data quality at this stage prevents errors from propagating downstream, making the subsequent analysis more reliable. For best practices in maintaining data quality, refer to resources like Dataversity’s guide on data quality.
Transforming Data for Actionable SEO & Content Creation
The transformation phase is where raw data gains its strategic value. Here, advanced algorithms and machine learning models perform tasks such as intent analysis to understand the user’s goal behind a search query. Entity extraction identifies key concepts and topics within SERP results, while sentiment analysis gauges the emotional tone of content. Keyword mapping organizes keywords into semantically related clusters, providing a structured foundation for content outlines.
This transformation converts disparate data points into semantically rich inputs. For example, a cluster of keywords around “best running shoes for flat feet” can be enriched with entities like “arch support,” “cushioning,” and “stability,” along with user intent signals (e.g., “review,” “buy,” “compare”). This enriched data directly informs content creation, ensuring that new content is comprehensive, relevant, and aligned with user expectations.
Building Your SEO Data Pipeline: Key Components & Architecture
Constructing an effective seo data pipeline requires a thoughtful selection of components and a robust architectural design. The choice between batch processing (for periodic updates) and real-time processing (for immediate insights) depends on your specific SEO needs and the velocity of data required. A typical architecture involves several interconnected layers, each serving a distinct function in the data flow.
At its core, an seo data pipeline needs reliable data sources, a mechanism for data ingestion, storage solutions, processing engines, and an output layer for reporting or direct content generation. Scalability and flexibility are key considerations, allowing the pipeline to adapt to increasing data volumes and evolving SEO requirements. This modular approach ensures that each component can be optimized or replaced without disrupting the entire system.
Essential Tools for SEO Data Pipeline Construction
The tools chosen for your seo data pipeline will significantly impact its efficiency and capabilities. These can range from open-source solutions to enterprise-grade platforms. For more insights into automating SEO tasks, explore resources on automated SEO workflows.

Advanced Data Transformation: From Raw SERP to Automated Content
The true power of an advanced seo data pipeline lies in its ability to transform raw SERP data not just into insights, but directly into structured, automated content. This goes beyond simple keyword reports, leveraging sophisticated multi-model AI architectures to understand the nuances of search intent and content structure. By integrating advanced natural language processing (NLP) and generation (NLG) capabilities, pipelines can now craft semantically rich content outlines and even draft initial content pieces.
Real-time SERP data processing plays a pivotal role here. Imagine a pipeline that continuously monitors SERP changes for target keywords. When a new featured snippet appears or a competitor updates their content, the pipeline can immediately analyze the semantic shifts, identify new entities, and understand the updated user intent. This real-time understanding directly impacts content structuring, allowing for dynamic adjustments to existing content or the rapid generation of new, highly relevant articles.
Multi-model AI, for instance, can combine textual analysis of SERPs with image recognition (for visual search elements) and even audio analysis (for voice search queries). This holistic approach provides a deeper understanding of user intent, enabling the pipeline to generate content that is not only textually optimized but also considers diverse search modalities. This capability is key to creating content that truly resonates with search engines and users alike, significantly improving content relevance and velocity. Learn more about leveraging AI in SEO workflows at multi-model AI SEO workflow.
Strategies for High-Volume Data: API Orchestration & Rate Limits
Operating an seo data pipeline at high volume presents unique challenges, particularly concerning API orchestration and managing rate limits. Advanced pipelines often interact with dozens of APIs from search engines, SEO tools, and internal systems. Efficient orchestration is critical to ensure data flows smoothly without hitting bottlenecks or incurring unnecessary costs. This involves intelligent scheduling, parallel processing, and robust error handling mechanisms.
Effective API orchestration requires a centralized control plane that manages API keys, monitors usage, and dynamically adjusts request frequencies. Tools like Apache Airflow or Prefect are invaluable for defining complex data workflows, allowing for dependencies, retries, and conditional logic. This ensures that if one API call fails, the entire pipeline doesn’t crash, and resources are not wasted on redundant requests.
Handling rate limits is a constant battle in high-volume data operations. Strategies include implementing exponential backoff algorithms, using proxy rotations to distribute requests, and leveraging distributed computing architectures. For example, distributing scraping tasks across multiple IP addresses or using cloud functions that can scale on demand helps circumvent per-IP or per-account rate limits. Furthermore, caching frequently accessed data reduces the need for repeated API calls, conserving limits and speeding up data retrieval. For a practical example of handling live SERP data, see our live SERP analysis case study.
Measuring ROI and Scaling Your SEO Data Pipeline
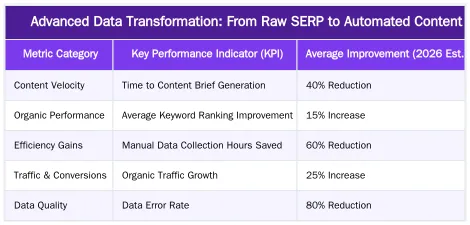
Demonstrating the return on investment (ROI) of an seo data pipeline is crucial for securing continued resources and justifying its development. Key performance indicators (KPIs) should directly reflect the pipeline’s impact on SEO objectives. Metrics such as increased content velocity (the speed at which new content is published), improved keyword rankings, higher organic traffic, and enhanced conversion rates are direct indicators of success. Additionally, tracking the reduction in manual labor hours for data collection and analysis provides a clear cost-saving benefit.
Scaling an seo data pipeline involves more than just increasing processing power; it requires a strategic approach to infrastructure, data governance, and team capabilities. As data volumes grow, transitioning from local databases to cloud-based data lakes or warehouses becomes essential for storage and query performance. Implementing robust data governance policies ensures data quality and compliance, which are critical for large-scale operations. Furthermore, investing in data engineering and analytics talent within your team is vital for maintaining and evolving the pipeline.
Regular performance reviews and A/B testing of pipeline components can identify areas for optimization. For instance, testing different data transformation models or SERP scraping configurations can yield significant improvements in efficiency and accuracy. By continuously monitoring and refining your pipeline, you can ensure it remains a powerful asset for your SEO strategy, capable of handling future growth and evolving market demands. For strategies on expanding content operations, visit scaling content operations.
The Future of SEO Data Pipelines: AI, ML, and Real-time Insights
The evolution of the seo data pipeline is inextricably linked with advancements in artificial intelligence and machine learning. In 2026 and beyond, these technologies will move beyond mere data processing to enable predictive analytics, adaptive content strategies, and hyper-personalized user experiences. The focus will shift from reactive analysis to proactive optimization, anticipating search trends and algorithm changes before they fully manifest.
AI and ML integration will empower pipelines to perform more sophisticated tasks, such as automatically identifying emerging entities, predicting keyword performance, and even generating entire content pieces that are semantically optimized for specific search intents. Real-time analytics, fueled by streaming data architectures, will allow for instantaneous adjustments to SEO campaigns based on live SERP fluctuations or user behavior signals. This means content can be dynamically updated, internal linking structures optimized, and technical issues flagged the moment they arise.
Furthermore, future seo data pipelines will likely incorporate advanced anomaly detection to quickly identify unusual drops in rankings or traffic, pinpointing the root cause with greater precision. The integration of large language models (LLMs) will enhance the pipeline’s ability to understand complex queries and generate highly nuanced content. This continuous feedback loop between data, AI, and content will create a truly intelligent SEO ecosystem, driving unprecedented levels of organic performance. For a deeper dive into AI’s role in data, explore resources like IBM’s guide to Artificial Intelligence.
Conclusion
Building a robust seo data pipeline is no longer an option but a strategic imperative for any business aiming for sustained organic growth in 2026. By automating the collection, transformation, and analysis of SERP data, organizations can unlock unparalleled efficiencies, drive content velocity, and gain a significant competitive advantage. From foundational ETL processes to advanced multi-model AI for content generation, these pipelines are the backbone of modern, data-driven SEO. Embrace the power of automated data to transform your SEO strategy and achieve superior results. Ready to elevate your SEO operations? Visit abdurrahmansimsek.com to explore how we can help you build and optimize your SEO data pipelines.
Frequently Asked Questions
What makes an SEO data pipeline architecture unique?
A unique seo data pipeline architecture often leverages multi-model AI to process live SERP data. This involves specialized models for intent analysis, entity extraction, and content structuring, creating semantically rich content that precisely matches search intent. Such advanced pipelines are crucial for transforming raw data into actionable insights.
How much content can an SEO data pipeline generate daily?
A well-configured seo data pipeline can generate 50-100 high-quality, data-driven articles daily. Each piece typically includes live competitor analysis, proper schema markup, and automated internal linking, significantly boosting content velocity. This automation frees up human resources for strategic tasks.
What data sources does an SEO data pipeline integrate?
An effective seo data pipeline integrates various critical data sources. These commonly include Google Search Console, Google Analytics, the Knowledge Graph API, and live SERP data. This comprehensive integration provides a holistic view of the search landscape and identifies valuable content opportunities.
Can an SEO data pipeline handle enterprise-scale operations?
Yes, a robust seo data pipeline is designed to scale horizontally for enterprise operations. It can manage millions of keywords and thousands of content pieces, ensuring consistent processing. Advanced queue management helps prevent API throttling and maintains efficiency.
How does an SEO data pipeline ensure content quality?
An seo data pipeline ensures high content quality through multiple integrated quality gates. These include SERP relevance scoring, E-E-A-T compliance checks, readability analysis, and factual accuracy validation using various AI models. This multi-layered approach guarantees that generated content is both relevant and authoritative.
Why is an SEO data pipeline considered a necessity today?
An seo data pipeline is crucial in today’s digital marketing landscape because it automates the collection, processing, and transformation of raw SERP data. This automation provides competitive advantage by streamlining SEO workflows, enhancing content velocity, and driving superior organic performance. It allows businesses to leverage structured data and advanced automation for better decision-making.
Ruxi Data brings together multi-model AI, automated website crawling, live indexation checks, topical authority mapping, E-E-A-T enrichment, schema generation, and full pipeline automation — from crawl to WordPress publish to social posting — all in one platform built for agencies and freelancers who run on results.


