
The Use of Nofollow and Robots Txt: Optimizing Clinic Crawl Control
The correct use of nofollow and robots txt is crucial for effective clinic website SEO. This guide clarifies how `robots.txt` directs search engine crawlers away from specific site sections, managing crawl budget and preventing irrelevant content from being indexed. Conversely, the `nofollow` attribute, alongside `sponsored` and `ugc`, signals to search engines not to pass link equity through specific hyperlinks, preserving your site’s authority. Mastering these search engine directives prevents indexing issues, optimizes crawl control, and ensures valuable medical content achieves proper visibility, especially for YMYL SEO.
Abdurrahman Şimşek, a Semantic SEO Strategist, provides expert insights into technical SEO best practices. This content offers actionable strategies for implementing crawl control directives effectively, ensuring your clinic’s digital presence is optimized for search engine discovery and patient engagement.
To explore your options, contact us to schedule your consultation. You can also reach us via: Book a Semantic SEO Audit, Direct WhatsApp Strategy Line: +90 506 206 86 86
For London’s elite medical clinics, mastering the technical nuances of SEO is paramount for visibility and patient acquisition. This guide delves into the correct use of nofollow and robots txt, two critical directives that govern how search engines interact with your clinic’s website. Understanding their distinct roles optimizes crawl budget, preserves link equity, and ensures valuable medical content is discovered by patients. Misusing these directives can lead to indexing issues, wasted crawl budget, and diluted link equity, especially for Your Money Your Life (YMYL) sites.
Understanding ‘nofollow’ vs. ‘robots.txt’: Essential Crawl Control for Clinic Websites
The distinction between ‘nofollow’ and ‘robots.txt’ is fundamental for effective search engine optimization, particularly for medical websites. While both influence how search engines interact with your site, they operate at different levels and serve distinct purposes. Correct application ensures search engines efficiently process medical content, avoiding wasted resources on irrelevant pages.
What is robots.txt and How Does it Function?
The `robots.txt` file is a text file located at the root of a website, acting as a protocol for search engine bots. It instructs crawlers which parts of a site they are permitted or forbidden to access. For a clinic website, this file can prevent search engines from crawling areas like internal search results, administrative login pages, or staging environments. It’s crucial to understand that `robots.txt` is a request, not a command. While major search engines like Google generally respect these directives, a page disallowed in `robots.txt` can still appear in search results if it is linked to from other indexed pages. Its primary role is to manage crawl budget, guiding bots to prioritize valuable content.
What is the ‘nofollow’ Attribute and Its Purpose?
The `nofollow` attribute (`rel=’nofollow’`) is applied to individual hyperlinks within the HTML of a webpage. Its purpose is to instruct search engines not to pass PageRank (link equity) through that specific link and not to use the link as an endorsement signal. Initially, `nofollow` was a blanket directive for untrusted content. In 2019, Google introduced two more specific attributes: `rel=’sponsored’` for paid links and `rel=’ugc’` for user-generated content. These attributes provide granular control and transparency, helping search engines understand link nature without necessarily treating it as a hard directive for crawling or indexing.
For a deeper dive into managing your site’s crawl efficiency, consider exploring strategies for fixing crawl budget issues.
When and How to Implement ‘nofollow’, ‘sponsored’, and ‘ugc’ Directives
Strategic application of crawl control directives is vital for medical websites to maintain SEO health and prioritize patient-facing content. Understanding when to use `robots.txt` versus link attributes is key to effective site management.
Strategic Use of robots.txt for Medical Websites
For clinic websites, `robots.txt` is best utilized for preventing the crawling of non-essential or sensitive areas. This conserves crawl budget, ensuring search engine bots focus on high-value content like procedure pages, surgeon bios, and educational articles. Examples include blocking internal search result pages, which often generate duplicate content, or administrative login portals. Large media files, if not intended for image search, can also be disallowed to reduce server load and improve crawl efficiency. Protecting sensitive patient data or non-public areas is paramount; `robots.txt` prevents their discovery by bots.

Applying ‘nofollow’, ‘sponsored’, and ‘ugc’ Attributes on Clinic Sites
Link attributes are applied directly to individual hyperlinks. For clinic websites, `rel=’nofollow’` is appropriate for untrusted external links, such as those in comment sections or forum posts where the destination’s quality cannot be guaranteed. The `rel=’sponsored’` attribute should be used for any paid placements, advertisements, or affiliate links to maintain transparency with search engines. For user-generated content, like patient testimonials, reviews, or forum discussions hosted on your site, `rel=’ugc’` is the recommended attribute. This signals to search engines that content originates from users, helping maintain trust and E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) while managing link equity flow from potentially unvetted sources.
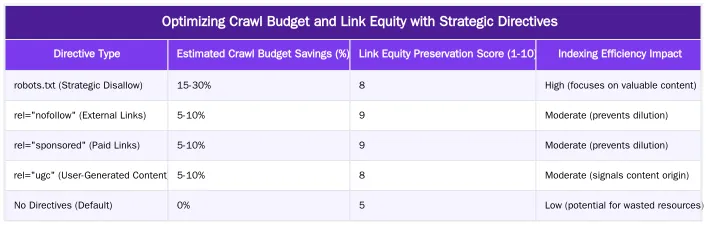
Optimizing Crawl Budget and Link Equity with Strategic Directives
For high-authority medical domains, the correct application of crawl control directives directly impacts a clinic’s crawl budget and link equity. Semantic SEO Strategist Abdurrahman Şimşek emphasizes that efficient crawling and precise link equity distribution are foundational to a robust online presence. These technical elements are crucial for search engines to efficiently discover and prioritize important medical content.
Reducing Search Engine ‘Cost of Retrieval’ for Complex Medical Content
Preventing unnecessary crawling of low-value pages via `robots.txt` and controlling link equity flow via `nofollow` attributes are integral to optimizing a website’s ‘Cost of Retrieval’. This concept, central to Abdurrahman Şimşek’s methodology, refers to the resources (time, processing power) search engines expend to crawl, process, and index a website. For complex medical content, where accuracy and depth are paramount, guiding search engines to the most authoritative pages reduces their effort. Minimizing crawling of irrelevant or duplicate content ensures clinics’ valuable, E-E-A-T-rich medical information is efficiently discovered and prioritized. This contributes to an efficient, effective technical SEO strategy for medical practices.
Learn more about reducing Cost of Retrieval for your medical website.
Protecting E-E-A-T and Topical Authority in YMYL Niches
In Your Money Your Life (YMYL) niches like healthcare, E-E-A-T and topical authority are critical ranking factors. Careful management of crawl directives prevents search engines from wasting resources on irrelevant or low-quality pages. This ensures valuable, E-E-A-T-rich medical content, such as detailed procedure guides or surgeon credentials, receives maximum attention and link equity. Directing search engine focus reinforces clinics’ topical authority, signaling to Google that their site is a comprehensive, trustworthy source of information within their medical specialty. This strategic approach is vital for maintaining high rankings and patient trust.
Common Pitfalls and Advanced Considerations for Medical Websites
Medical websites face unique challenges in SEO, often requiring a nuanced approach to crawl control. Beyond basic implementation, understanding common pitfalls and advanced scenarios is crucial for optimal search performance and protecting sensitive information.
The ‘robots.txt’ vs. ‘noindex’ Dilemma: Avoiding Indexation Traps
A common misconception is that disallowing a page in `robots.txt` prevents it from being indexed. While `robots.txt` prevents crawling, it does not definitively prevent indexing if other pages link to the disallowed URL. Search engines can still discover and index the URL, though without content. For sensitive or private clinic content that must not appear in search results, the `noindex` meta tag (``) is the definitive solution. This tag, placed in the “ section of the page, instructs search engines not to index the page, regardless of external links. It’s vital to allow crawling of pages with a `noindex` tag so search engine bots can discover and process the directive. For more details on blocking indexing, refer to Google’s official documentation.
Managing User-Generated Content (UGC) and Patient Reviews
Clinic websites often feature user-generated content, such as patient testimonials, reviews, or even forum discussions. Properly managing these links is essential for E-E-A-T and link equity. The `rel=’ugc’` attribute is specifically designed for this purpose. Applied to links within user-generated content, it signals to search engines that content was created by users, not the site owner. This helps maintain trust and transparency, especially in YMYL contexts where content authorship is scrutinized. While `ugc` is a hint, it helps Google understand the link’s nature, allowing you to benefit from genuine patient feedback without implicitly endorsing every external link a user might include. For further reading on these attributes, see this article on Google’s link attributes.
Auditing and Monitoring Your Crawl Control Directives for SEO Health
Regular auditing and monitoring of crawl control directives are non-negotiable for maintaining a medical website’s SEO health. Misconfigurations can lead to significant indexing issues, impacting visibility and patient acquisition. Establishing a routine for these checks ensures the technical foundation remains robust.
Tools and Techniques for Reviewing robots.txt and Nofollow Links
Several tools can assist clinics in auditing their crawl control implementations. Google Search Console’s `robots.txt` Tester is invaluable for identifying syntax errors or unintended disallow directives. Log file analysis provides direct insights into how search engine bots interact with your site, revealing if disallowed pages are still requested or if important pages are overlooked. Site crawlers, such as Screaming Frog, identify all `nofollow`, `sponsored`, and `ugc` links on your site, allowing review of their application. Regularly checking these elements helps diagnose crawl issues and ensures directives are functioning as intended. For advanced diagnostics, consider implementing log file analysis to gain deeper insights into bot behavior.
Regular Maintenance for Optimal Technical SEO Performance
Establishing a routine for reviewing `robots.txt` and link attributes is crucial. This is important after website updates, migrations, or new content section launches. A clean technical foundation is paramount for YMYL sites, where accuracy and trust are heavily weighted. Regular checks prevent accidental blocking of critical pages or unintended passing of link equity. Proactive maintenance ensures search engines efficiently crawl, index, and rank valuable medical content, supporting your clinic’s digital strategy and patient outreach efforts.
Partner with a Semantic SEO Strategist for Technical Excellence
The intricacies of technical SEO, especially for medical clinics in competitive markets like London, demand specialized expertise. Correctly implementing directives like `nofollow` and `robots.txt` is just one facet of building a high-performing, algorithm-proof website. A Semantic SEO Strategist understands how these technical elements integrate with broader content architecture and entity modeling to achieve topical authority and optimize for search engine ‘Cost of Retrieval’.
Conclusion
Mastering the use of nofollow and robots txt is a foundational aspect of technical SEO for medical clinics. These directives, applied correctly, are powerful tools for managing crawl budget, preserving link equity, and ensuring valuable medical content is prioritized by search engines. From protecting sensitive administrative areas with `robots.txt` to transparently managing user-generated content and sponsored links with `nofollow`, `sponsored`, and `ugc` attributes, each decision contributes to your site’s SEO health and E-E-A-T. For London’s elite medical practices, a meticulous approach to these technical details is a strategic imperative for sustained online visibility and patient acquisition.
To ensure your clinic’s website is technically optimized for peak performance and semantic authority, contact us today. You can also Book a Semantic SEO Audit or reach out directly via our Direct WhatsApp Strategy Line: +90 506 206 86 86.
Frequently Asked Questions
What is the fundamental difference in the use of nofollow and robots txt for clinic websites?
The `robots.txt` file instructs search engines on which URLs they are not permitted to *crawl*, while the `nofollow` attribute on a link tells them not to pass link equity or use that link as an endorsement. Understanding the distinct use of nofollow and robots txt is crucial because a page blocked by `robots.txt` can still be indexed if linked externally, whereas `noindex` is needed for definitive exclusion from search results.
How does the use of nofollow and robots txt impact a clinic’s crawl budget and link equity?
Strategic implementation of these directives significantly optimizes crawl budget by preventing search engines from wasting resources on unimportant pages like admin areas or duplicate content. It also preserves link equity by ensuring valuable “link juice” is not passed to irrelevant or sponsored external sites. This helps focus search engine attention on your most important patient-facing content.
When should a clinic website specifically consider the use of nofollow and robots txt directives?
Clinic websites should use `robots.txt` to block access to sensitive areas like patient portals, internal search results, and parameter-driven URLs that create duplicate content. The `nofollow` attribute (or `sponsored`/`ugc`) should be applied to paid links, user-generated content links, and any external links you do not wish to endorse. This ensures compliance and efficient resource allocation.
What are common pitfalls in the implementation of these crawl directives?
A common pitfall is blocking pages with `robots.txt` that you actually want indexed, or conversely, expecting `robots.txt` to prevent indexing (which it doesn’t guarantee). Another mistake is using `nofollow` on internal links, which is an outdated practice for controlling crawl flow. Incorrect implementation can lead to important pages being missed or irrelevant pages appearing in search results.
If a page is blocked by robots.txt, will it still appear in search results?
Not necessarily. If another website links to your blocked page, Google can still find and index it without crawling the content, often showing just the URL in search results. To ensure a page is never indexed, you must allow it to be crawled and use a `noindex` meta tag.
How can Abdurrahman Şimşek help optimize the use of nofollow and robots txt for my medical practice?
Abdurrahman Şimşek, a Semantic SEO Strategist with 10+ years of experience, specializes in technical SEO for medical clinics. He can perform a detailed audit to ensure the correct use of nofollow and robots txt, optimizing your crawl budget and protecting your site’s link equity. For expert guidance, you can book a Semantic SEO Audit or reach out via WhatsApp at +90 506 206 86 86.
Ruxi Data brings together multi-model AI, automated website crawling, live indexation checks, topical authority mapping, E-E-A-T enrichment, schema generation, and full pipeline automation — from crawl to WordPress publish to social posting — all in one platform built for agencies and freelancers who run on results.


