
Crawl Budget Optimization: Enhancing Enterprise Site Indexability
Crawl budget optimization is essential for enterprise websites to ensure efficient indexing and search visibility. This article outlines a structured technical workflow for identifying, prioritizing, and resolving crawl budget inefficiencies on large sites. It details how to manage Googlebot’s crawling behavior, prevent wasted resources on low-value pages, and prioritize high-value content. Effective crawl budget management directly impacts indexability, improving organic performance by ensuring critical pages are discovered and updated promptly within complex site architectures. The content provides actionable strategies for technical SEO professionals.
This content provides a comprehensive guide to technical SEO strategies for enterprise websites, focusing on practical applications for managing large-scale digital properties. It offers insights into optimizing site performance and visibility through efficient resource allocation.
To explore your options, contact us to schedule your consultation.
For large enterprise websites, effective crawl budget optimization is a critical technical SEO endeavor. This process involves strategically managing how search engine bots, like Googlebot, crawl and index a vast number of pages, ensuring valuable content is discovered efficiently while minimizing wasted crawl resources on low-priority or duplicate content. Addressing crawl budget problems directly impacts indexability, search visibility, and ultimately, organic performance for complex digital properties. This article outlines a structured, technical workflow designed to identify, prioritize, and resolve crawl budget inefficiencies, providing actionable strategies for enterprise-level SEO professionals.
Understanding Crawl Budget and Its Enterprise Significance
Crawl budget refers to the number of URLs Googlebot can and wants to crawl on a website within a given timeframe. It comprises two main components: crawl rate limit and crawl demand. The crawl rate limit dictates how many concurrent connections Googlebot can use and the delay between fetches, determined by server health and Google’s assessment of site capacity. Crawl demand, conversely, is influenced by a site’s popularity, freshness of content, and the perceived value of its pages.
For enterprise websites, which often host millions of URLs, managing this budget is paramount. Inefficient crawling can lead to critical pages being discovered slowly or not at all, directly impacting indexability and search engine rankings. A large site might have numerous low-value pages (e.g., filtered results, old internal search pages, duplicate content) that consume a disproportionate share of the crawl budget, diverting Googlebot from high-value, revenue-generating content. Understanding and optimizing this resource is a foundational aspect of large site SEO.
Effective crawl budget management ensures that Googlebot prioritizes the most important content, leading to faster indexation of new or updated pages. This is particularly crucial for dynamic sites like e-commerce platforms or news publishers where content changes frequently. As detailed by Google Search Central, maintaining a healthy crawl environment is essential for comprehensive indexing. For further reading on Googlebot’s operations, consult the official Google Search Central documentation on Google crawlers.
Identifying Crawl Budget Issues on Large Websites
Detecting crawl budget problems on an enterprise scale requires a systematic approach. The primary tool for initial assessment is Google Search Console (GSC). The “Crawl Stats” report within GSC provides insights into Googlebot’s activity on a site, including the total number of crawled pages, total download size, and average response time. Spikes in crawled pages without corresponding content growth, or a decline in crawled pages for a dynamic site, can signal issues.
Beyond GSC, log file analysis is indispensable for a granular understanding of Googlebot’s behavior. Server log files record every request made to a website, including those from search engine crawlers. By analyzing these logs, SEO professionals can identify:
- Which pages Googlebot crawls most frequently.
- The HTTP status codes Googlebot receives (e.g., 200 OK, 404 Not Found, 5xx Server Error).
- Crawl patterns and paths taken by Googlebot.
- Wasted crawl on low-value or non-existent pages.
Symptoms of crawl budget issues include slow indexation of new content, important pages not appearing in search results, or a significant portion of the crawl budget being spent on pages with little to no SEO value. For instance, if log files show Googlebot repeatedly hitting 404 pages or crawling thousands of faceted navigation URLs that are blocked by robots.txt, it indicates inefficient resource allocation. Understanding these patterns is the first step toward effective crawl budget optimization.
Core Strategies for Effective Crawl Budget Optimization
Effective crawl budget optimization focuses on guiding search engine crawlers to the most valuable content while conserving resources. This involves a combination of technical adjustments and content prioritization. By implementing these strategies, enterprise websites can improve their indexability and ensure critical pages are discovered and ranked efficiently.
Key strategies include:
- Improve Site Speed and Performance: Faster loading times reduce the time Googlebot spends on each page, allowing it to crawl more URLs within the same timeframe. This includes optimizing server response times, image compression, and efficient code delivery.
- Manage Indexability with Robots.txt and Meta Directives: Use
robots.txtto block crawlers from accessing low-value sections (e.g., internal search results, admin pages, duplicate content). Employnoindexmeta tags or HTTP headers for pages that should be crawled but not indexed, such as paginated archives or certain user-generated content. - Optimize Internal Linking Structure: A clear, hierarchical internal linking structure helps distribute PageRank and guides crawlers to important pages. Ensure high-value content is linked from prominent, easily accessible locations.
- Implement Canonicalization: Use
rel="canonical"tags to consolidate ranking signals for duplicate or near-duplicate content, preventing crawl budget waste on redundant URLs. This is crucial for e-commerce sites with product variations. - Control Faceted Navigation: For sites with extensive filtering options, manage the proliferation of parameter-based URLs. Use a combination of
robots.txt,noindex, and URL parameter handling in GSC to prevent crawlers from getting lost in infinite filter combinations. - Leverage Server-Side Rendering (SSR) or Prerendering: For JavaScript-heavy sites, SSR or prerendering ensures that Googlebot can easily access and render content without relying on client-side execution, improving crawlability and indexability.
Essential Tools for Crawl Budget Management
Managing crawl budget effectively requires a suite of specialized tools that provide insights into crawler behavior and site structure. These tools range from those provided by search engines to third-party solutions designed for deep technical analysis.
Google Search Console (GSC): This free tool from Google is fundamental. The “Crawl Stats” report offers an overview of Googlebot’s activity, including the number of pages crawled per day, download size, and average response time. It helps identify trends and potential issues at a high level.
Log File Analyzers: These tools process server access logs to show exactly what Googlebot (and other bots) crawled, when, and what status codes were returned. Popular options include Screaming Frog Log File Analyser, Splunk, or custom scripts for large datasets. They are critical for identifying wasted crawl budget on 404s, redirects, or low-value pages.
Site Crawlers: Tools like Screaming Frog SEO Spider, Sitebulb, or DeepCrawl simulate a search engine crawl of your website. They help identify broken links, redirect chains, duplicate content, orphaned pages, and other structural issues that can impact crawl efficiency. These crawlers are essential for auditing site architecture and internal linking.
Performance Monitoring Tools: Solutions like Google Lighthouse, PageSpeed Insights, or WebPageTest help diagnose site speed issues, which directly influence crawl rate. Improving Core Web Vitals can positively impact how much Googlebot crawls.
Here’s a comparison of common tool types and their primary benefits:

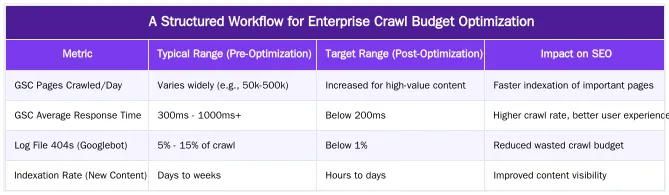
A Structured Workflow for Enterprise Crawl Budget Optimization
Implementing a systematic workflow is crucial for effective crawl budget optimization on enterprise websites. This structured approach ensures that efforts are prioritized, measurable, and sustainable. For complex sites, a phased methodology helps manage the scope and impact of changes.
-
Phase 1: Discovery & Audit
Begin by gathering comprehensive data. Analyze Google Search Console’s Crawl Stats report for high-level trends and errors. Conduct a deep log file analysis to understand Googlebot’s actual crawling behavior, identifying frequently crawled low-value pages, 404s, and redirect chains. Perform a full site crawl using a robust crawler to map site architecture, identify duplicate content, orphaned pages, and internal linking issues. This phase establishes a baseline and highlights areas of concern.
-
Phase 2: Prioritization & Strategy Development
Based on audit findings, categorize issues by impact and effort. Prioritize problems that waste significant crawl budget on high volumes of low-value URLs or prevent critical pages from being crawled. Develop specific strategies for each identified issue, such as implementing robots.txt directives, canonical tags, or improving internal linking. Consider the business impact of each change.
-
Phase 3: Implementation & Technical Execution
Execute the defined strategies. This might involve updating
robots.txtfiles, addingnoindextags to specific templates, refining URL parameters in GSC, optimizing server response times, or restructuring internal links. For large sites, this often requires coordination with development teams. Ensure changes are tested in a staging environment before deployment. -
Phase 4: Monitoring & Iteration
After implementation, continuously monitor the impact of changes. Regularly review GSC Crawl Stats, conduct ongoing log file analysis, and perform periodic site crawls. Track key performance indicators (KPIs) such as indexation rates, crawl error reductions, and organic traffic shifts. This iterative process allows for adjustments and ensures long-term crawl efficiency. For a more detailed guide on this process, refer to optimizing crawl budget workflow.
This workflow provides a clear roadmap for enterprise teams to manage their crawl budget effectively, transforming complex challenges into actionable improvements.
Technical Factors Influencing Crawl Efficiency
Several technical elements profoundly influence how efficiently search engine bots crawl a website. Understanding these factors is key to successful crawl budget optimization.
-
Site Architecture
The structure of a website dictates how easily crawlers can discover pages. A flat architecture, where important pages are only a few clicks from the homepage, generally facilitates better crawling than a deep, complex structure. Logical categorization and clear navigation paths help Googlebot understand the site’s hierarchy and prioritize content.
-
Internal Linking
Internal links are the pathways for crawlers. A robust and well-distributed internal linking strategy ensures that PageRank flows effectively throughout the site, signaling the importance of certain pages. Orphaned pages, lacking internal links, are less likely to be discovered and crawled regularly. Anchor text also provides context to crawlers about the linked content.
-
Canonicalization
Duplicate content, even if slight variations exist (e.g., different URLs for the same product), can waste crawl budget. Canonical tags (
rel="canonical") tell search engines which version of a page is the preferred one, consolidating ranking signals and preventing crawlers from spending resources on redundant content. This is a critical component for large e-commerce sites. -
Faceted Navigation
For sites with extensive filtering options, faceted navigation can generate an exponential number of unique URLs. Without proper management (e.g., using
robots.txt,noindex, or URL parameter handling in GSC), crawlers can get trapped in these infinite combinations, consuming significant crawl budget on low-value pages. For more insights on fixing crawl budget issues, see this resource. -
Core Web Vitals and Site Speed
Google has explicitly stated that faster sites can be crawled more efficiently. Pages with good Core Web Vitals (Largest Contentful Paint, Cumulative Layout Shift, First Input Delay) and overall fast loading times allow Googlebot to process more pages within its allotted crawl rate limit. Server response time is a direct factor in crawl rate.
These technical considerations are interconnected, and a holistic approach to their optimization yields the best results for crawl efficiency.
Measuring Success and KPIs for Crawl Budget Initiatives
To validate the effectiveness of crawl budget optimization efforts, it is essential to track specific Key Performance Indicators (KPIs). These metrics provide tangible evidence of improvement and guide ongoing strategy.
Google Search Console (GSC) Crawl Stats: This is the primary source for monitoring Googlebot’s activity. Key metrics to track include:
- Pages crawled per day: An increase in crawled pages, especially for high-value content, indicates improved efficiency.
- Total download size: A reduction in download size per page suggests better resource utilization.
- Average response time: Lower response times mean Googlebot can crawl more pages faster.
- Crawl errors: A decrease in 4xx and 5xx errors signifies a healthier site and less wasted crawl budget.
Log File Analysis Data: For granular insights, log files offer crucial KPIs:
- Crawl frequency on important pages: Increased crawl frequency on high-priority URLs confirms successful prioritization.
- Crawl distribution: A shift in crawl activity from low-value to high-value sections of the site.
- Status codes served to Googlebot: Monitoring the percentage of 200 OK, 301/302 redirects, and 404 Not Found responses helps identify and resolve issues that waste crawl budget.
Indexation Rate: Track the number of indexed pages in GSC or through site queries. An increase in indexed pages, particularly for new or updated content, indicates that crawl budget is being effectively utilized for discovery and inclusion in the search index.
Organic Traffic and Rankings: While not a direct measure of crawl budget, improvements in organic traffic, keyword rankings, and visibility for key pages can be an indirect indicator of successful crawl budget management, as better indexation often correlates with improved search performance.
Regularly compiling and analyzing these KPIs allows enterprise SEO teams to demonstrate the ROI of their crawl budget optimization efforts and make data-driven decisions for continuous improvement.
Conclusion
Effective crawl budget optimization is a continuous and essential technical SEO practice for enterprise websites. By systematically identifying issues through log file analysis and GSC, implementing strategic technical adjustments, and rigorously monitoring performance, large organizations can ensure their valuable content is efficiently discovered and indexed by search engines. This structured approach not only conserves crawling resources but also directly contributes to improved search visibility and organic performance. Mastering crawl budget management is a cornerstone of sustainable enterprise SEO success in 2026 and beyond.
For expert assistance in developing and implementing a tailored crawl budget optimization strategy for your enterprise website, visit abdurrahmansimsek.com.
Frequently Asked Questions
Why is crawl budget optimization critical for large enterprise websites?
Crawl budget refers to the number of pages Googlebot can and wants to crawl on your site within a given timeframe. For enterprise websites with thousands or millions of pages, effective crawl budget optimization ensures that important content is discovered and indexed efficiently. This prevents valuable pages from being overlooked and improves overall search visibility.
How can Ruxi Data assist with crawl budget optimization?
Ruxi Data’s automation infrastructure helps identify crawl inefficiencies through detailed log file analysis. It can prioritize critical pages and automate internal linking and schema markup to guide crawlers more effectively. This ensures optimal resource allocation and improves the site’s indexability.
What technical issues commonly hinder effective crawl budget optimization?
Common technical issues include duplicate content, broken links, orphan pages, and unoptimized faceted navigation. Poor internal linking and an abundance of low-value pages also force crawlers to spend resources on non-essential content. Addressing these issues is key to improving how search engines interact with your site.
How does site architecture contribute to successful crawl budget optimization?
A well-structured site architecture with clear hierarchies and logical internal linking helps Googlebot navigate and understand your site efficiently. This directs search engine resources to important sections and pages, improving overall indexability. A robust architecture is foundational for efficient crawling.
Is managing crawl resources more important for SaaS or e-commerce platforms?
Managing crawl resources is crucial for both, but particularly for large e-commerce sites with dynamic product pages and SaaS platforms with extensive documentation or user-generated content. Efficiently guiding crawlers ensures all valuable pages are considered for indexing. This directly impacts the discoverability of critical content.
What role do sitemaps play in managing search engine crawling?
XML sitemaps guide search engines to important pages you want indexed, though they don’t guarantee crawling. They act as a strong suggestion, helping Googlebot discover new or updated content more quickly and efficiently. Sitemaps are a vital tool for complementing efforts to optimize how bots explore your site.
Ruxi Data brings together multi-model AI, automated website crawling, live indexation checks, topical authority mapping, E-E-A-T enrichment, schema generation, and full pipeline automation — from crawl to WordPress publish to social posting — all in one platform built for agencies and freelancers who run on results.