
Canonical Tag Automation: Fix Duplicate Content at Scale
Canonical tag automation is a critical strategy for resolving duplicate content issues at scale, ensuring robust SEO performance. This guide details how automated systems, particularly AI-driven solutions, precisely identify and apply canonical tags to consolidate link equity and enhance search engine visibility. Readers will learn to overcome the inefficiencies of manual canonicalization, effectively manage URL parameters, content syndication, and pagination, and preserve valuable link equity across large, dynamic websites. Implementing this approach is essential for maximizing SEO efforts and maintaining strong rankings in competitive digital landscapes.
This article provides an authoritative overview of advanced SEO strategies, focusing on practical solutions for complex website challenges. It offers insights into leveraging technology to optimize site architecture and improve search engine crawlability and indexing, reflecting a commitment to effective digital presence management.
To explore your options, contact us to schedule your consultation.
In the complex world of SEO, duplicate content can silently erode your site’s authority and rankings. This guide explores canonical tag automation, a powerful strategy to fix duplicate content issues at scale, ensuring your link equity is preserved and your SEO efforts are maximized. We will delve into how automated systems, particularly AI-driven solutions, overcome the limitations of manual canonicalization, providing precision and efficiency for large, dynamic websites. Understanding this approach is critical for maintaining robust search engine visibility in 2026.
What is Canonical Tag Automation and Why Does it Matter?
Canonical tag automation is the process of using software, often powered by AI, to automatically detect duplicate or similar content on a website and apply the correct canonical tags. This tells search engines which version of a page is the preferred one, consolidating link equity and improving SEO efficiency. Duplicate content arises from various sources, including URL parameters, content syndication, and pagination, confusing search engines about which page to rank.
A canonical tag (<link rel="canonical" href="preferred-url">) is an HTML element that specifies the “master” version of a page. When multiple URLs serve identical or very similar content, this tag ensures that all link equity and ranking signals are consolidated to the preferred URL. This prevents dilution of SEO value and helps search engines crawl and index your site more efficiently. For large websites, managing these tags manually becomes impractical, making canonical tag automation an essential strategy for preserving SEO value and preventing ranking dilution.

How Does Canonical Tag Automation Work in Practice?
Canonical tag automation systems leverage sophisticated algorithms and artificial intelligence to streamline the process of identifying and resolving duplicate content. These systems typically begin by crawling and analyzing a website’s entire content inventory. They look for patterns, content similarity, and URL structures that commonly lead to duplicate pages. This comprehensive analysis forms the foundation for accurate canonicalization.
Once potential duplicates are identified, the automation system determines the most authoritative or preferred version of the content. This decision is based on various factors, including page authority, internal linking structure, and content completeness. The system then automatically generates and implements the appropriate canonical tags, pointing all duplicate versions to the chosen canonical URL. This ensures that search engines correctly attribute all SEO signals to the intended page.
Identifying Duplicate Content & Canonical URLs at Scale
At scale, identifying duplicate content requires more than simple URL matching. Automated systems employ advanced algorithms, including natural language processing (NLP) and content fingerprinting, to detect semantic similarity between pages. This allows them to catch near-duplicates that might have slight variations but essentially convey the same information. By analyzing content, metadata, and internal linking patterns, AI can accurately select the authoritative version, even across vast content repositories.
Handling Complex Scenarios: Parameters, Pagination & Syndication
One of the most significant advantages of canonical tag automation is its ability to intelligently manage complex URL structures. Dynamic URL parameters, often used for tracking, filtering, or sorting (e.g., ?color=red&size=M), can create countless duplicate URLs. Automated systems analyze these parameters, consolidating them to a clean, canonical URL. Similarly, for paginated series (e.g., /category/page/2/), automation ensures that the correct canonical strategy is applied, often pointing to the first page or using rel="next" and rel="prev" attributes in conjunction with canonicals. For content syndication, where your content appears on other sites, cross-domain canonicals can be automatically generated to ensure your original content receives the SEO credit. This intelligent handling helps optimize crawl budget with canonical tags and prevents search engine confusion.
Measuring Success: What to Expect After Automating Canonical Tags
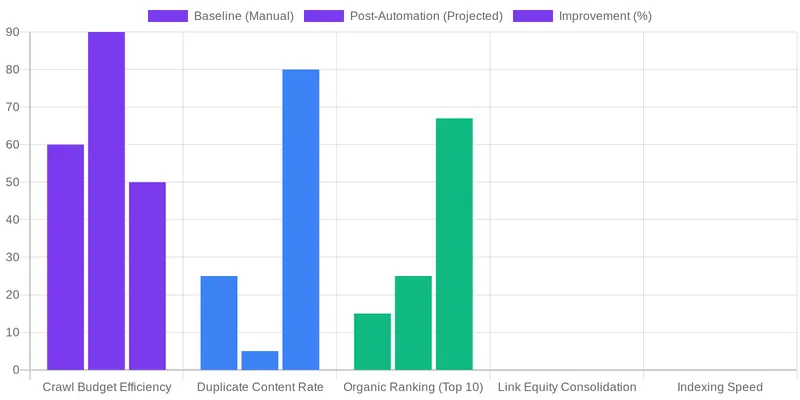
Implementing canonical tag automation yields several measurable benefits that significantly impact your SEO performance. One of the most immediate improvements is enhanced crawl budget efficiency. By clearly signaling preferred pages, search engines spend less time processing duplicate content, allowing them to discover and index new or updated content more quickly. This leads to a more effective use of your site’s crawl budget, which is crucial for large websites.
You can also expect to see improved search engine rankings for your canonical pages. By consolidating link equity from all duplicate versions, the preferred page gains a stronger authority signal, leading to better visibility in search results. This consolidation also provides clearer analytics, as traffic and engagement metrics are attributed to a single, authoritative URL. Key metrics to track include:
- Duplicate Content Rate: A significant reduction in identified duplicate pages.
- Crawl Stats: Increased crawl efficiency and reduced time spent on non-canonical URLs in Google Search Console.
- Ranking Improvements: Higher positions for target keywords on canonical pages.
- Organic Traffic: Growth in organic traffic to canonical URLs.
- Index Coverage: Fewer “Excluded by canonical tag” or “Duplicate, Google chose different canonical than user” warnings.
These improvements contribute to stronger technical E-E-A-T signals, demonstrating to search engines that your site is well-structured and authoritative. For a deeper understanding of how search engines process content, resources like Wikipedia’s article on Search Engine Optimization provide valuable context on the mechanisms at play.
Ready to Scale Your SEO? Automate Your Canonical Strategy Today
The challenges of duplicate content are only growing as websites become more complex and dynamic. Embracing canonical tag automation is no longer an option but a necessity for businesses aiming to optimize their SEO at scale. By leveraging AI-driven solutions, you can ensure precision, efficiency, and consistent application of canonical tags across your entire digital footprint.
Don’t let duplicate content dilute your SEO efforts or waste valuable crawl budget. Take control of your site’s authority and rankings. Explore how Ruxi Data’s advanced canonical tag automation can transform your SEO strategy, consolidate your link equity, and drive measurable results. Future-proof your website’s search performance starting today.
Conclusion
Canonical tag automation is a transformative solution for managing duplicate content issues at scale, offering a significant upgrade from error-prone manual methods. By intelligently identifying canonical URLs and applying the correct tags, automated systems preserve link equity, enhance crawl budget efficiency, and ultimately improve search engine rankings. For large and dynamic websites, this automation is indispensable for maintaining a robust SEO presence in 2026 and beyond. Ready to streamline your SEO and ensure your content gets the recognition it deserves? Visit abdurrahmansimsek.com to discover how AI-powered solutions can optimize your canonical strategy.
Frequently Asked Questions
How does Ruxi Data facilitate canonical tag automation?
Ruxi Data employs AI to analyze content similarity across your website, identifying duplicate or near-duplicate pages. This enables precise canonical tag automation, ensuring the correct canonical tag points to the primary content version and preserves valuable link equity.
Does canonical tag automation effectively manage dynamic URL parameters?
Yes, canonical tag automation systems intelligently analyze traffic patterns and content variations to handle dynamic URL parameters. This process automatically canonicalizes parameter variations to their main URLs, effectively preventing duplicate content issues and maintaining SEO integrity.
What is the typical ROI of implementing canonical tag automation?
Implementing canonical tag automation can yield significant ROI by recovering 15-30% of lost link equity from duplicate pages. It also drastically reduces manual audit time by up to 90%, preventing indexation bloat and improving overall site performance.
Can canonical tag automation be applied to multilingual websites?
Yes, canonical tag automation is highly effective for multilingual sites. Systems like Ruxi Data support the combination of hreflang and canonical tags, automatically managing language variations while ensuring proper canonical relationships for international SEO.
How quickly do the effects of canonical tag automation become visible in search rankings?
Google typically processes canonical signals within 2-4 weeks. However, with integrations like IndexNow, the discovery of changes made by canonical tag automation can be accelerated, often leading to ranking consolidation within 7-10 days.
Ruxi Data brings together multi-model AI, automated website crawling, live indexation checks, topical authority mapping, E-E-A-T enrichment, schema generation, and full pipeline automation — from crawl to WordPress publish to social posting — all in one platform built for agencies and freelancers who run on results.


